내가 볼려고 정리하는 Couchbase ~!
![]()
특징
카우치베이스의 특징을 알아보겠습니다.
- NoSQL
- Memcached 기반
- JSON document database
- SQL 지원
- Schema-less
- Indexing
- 쉬운 확장성
- 다양한 SDK 지원
URLs.
제가 자주가는 사이트를 모아봤습니다.
- 공식 사이트 https://www.couchbase.com
- Learn > Blog https://www.couchbase.com/blog/
- 레퍼런스 ex)집계 함수 https://docs.couchbase.com/server/current/n1ql/
- couchbase java client 2.7.23 https://docs.couchbase.com/sdk-api/
- Array Indexing https://docs.couchbase.com
- java SDK 2.2 https://docs-archive.couchbase.com/java-sdk/2.2/
- java SDK 3.4 https://docs.couchbase.com/java-sdk/
- 국내 블로그 https://couchbase.tistory.com/
- N1QL
- tutorials https://query-tutorial.couchbase.com/tutorial
- Get Started https://docs.couchbase.com/server/current/getting-started/
- query https://docs.couchbase.com/java-sdk/current/
- SQL++ Language Reference index
- SQL++ Language Reference selectclause
- N1QL https://www.baeldung.com/n1ql-couchbase
설치 환경
MacBook Pro 16
MacOS Ventura 13.4.1
칩 Apple M1 Pro
메모리 16GB
Download
카우치베이스 공홈에서 설치 안내 페이지를 제공합니다.
https://docs.couchbase.com/server/current/install/macos-install.html
안내 페이지에 있는 downloads page 경로로 이동합니다.
Server 를 선택하시고요.
Version은 최신 버전을 선택했습니다.
os 는 MacOS ARM64 를 선택했습니다.
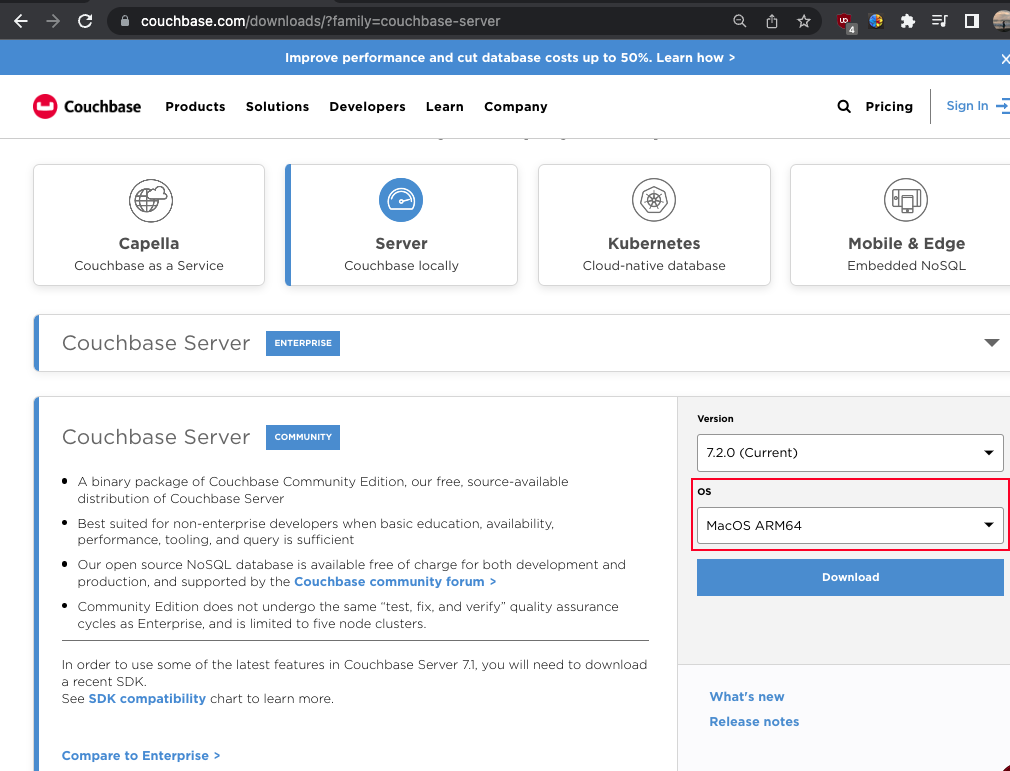
CPU 타입이 궁금하시다면 아래와 같이 확인해보시면 됩니다.
마지막에 arm64가 있군요.
$ uname -a
Darwin AL01599787.local 22.5.0 Darwin Kernel Version 22.5.0: Thu Jun 8 22:22:20 PDT 2023; root:xnu-8796.121.3~7/RELEASE_ARM64_T6000 arm64
Install
다운로드 받은 설치파일을 실행합니다.
Server 답게(?) 1G 용량을 자랑하는군요.
인터넷에서 다운로드 한 파일 안내가 나오는군요.
설치가 무척 쉽습니다. 이제 설정을 할 차례이군요.
인터넷 브라우저 http://127.0.0.1:8091/ui/index.html 에서 진행해 보아요.
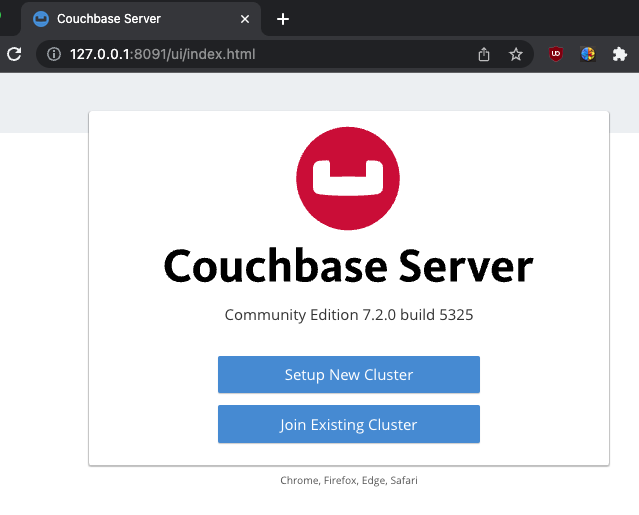
카우치베이스는 클러스터가 디폴트입니다.
클러스터의 이름을 적어주세요.
서비스명을 적어주거나 확장가능성을 고려해서 적어주시면 되겠네요.
관리자 이름과 관리자 비밀번호를 적어주세요. (ex. Administrator/couchbase)
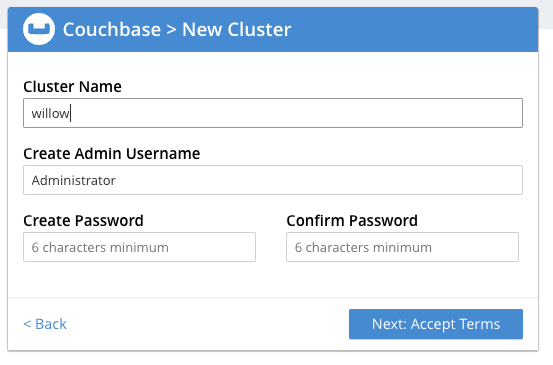
약관동의 체크, 사용정보 제공은 체크해제 하였습니다.

Defaults 설정하는 버튼과 직접 설정하는 버튼이 있습니다.
직접 설정하는 버튼이 활성되어 있습니다.
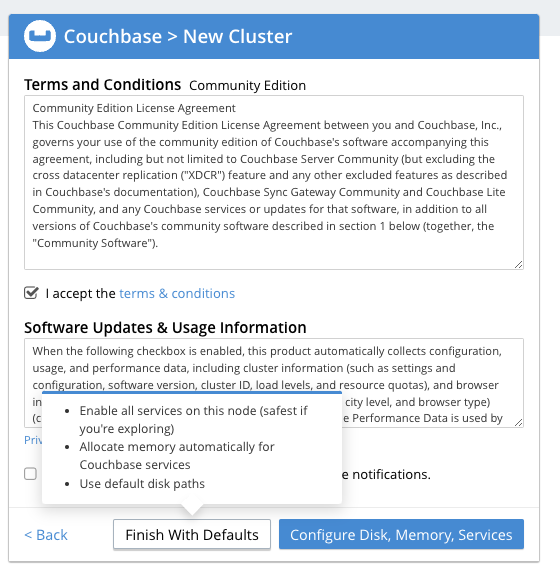
직접 설정 버튼을 선택한 다음 화면입니다. 기본값으로 진행합니다.
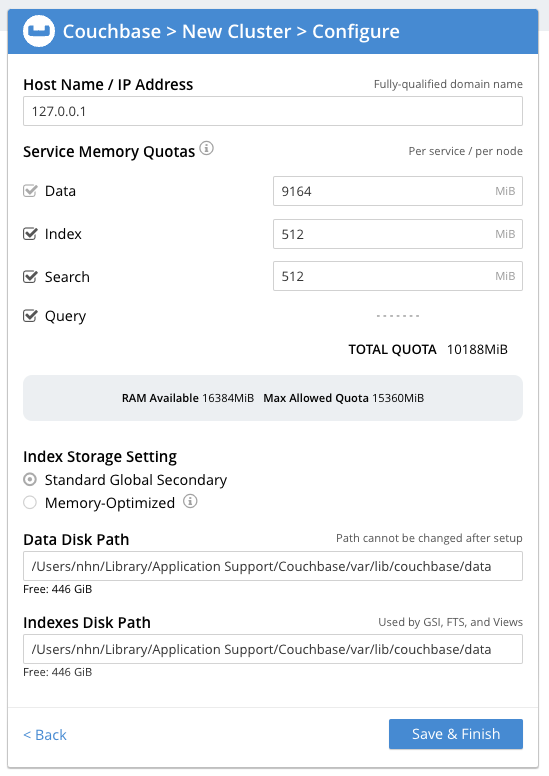
설정 완료되어 Couchbase 서버 정상 동작 화면이 나왔습니다.
버킷이 아직 하나도 없는 상태이군요.
샘플 버킷을 제공하는군요.
설치해볼까요?
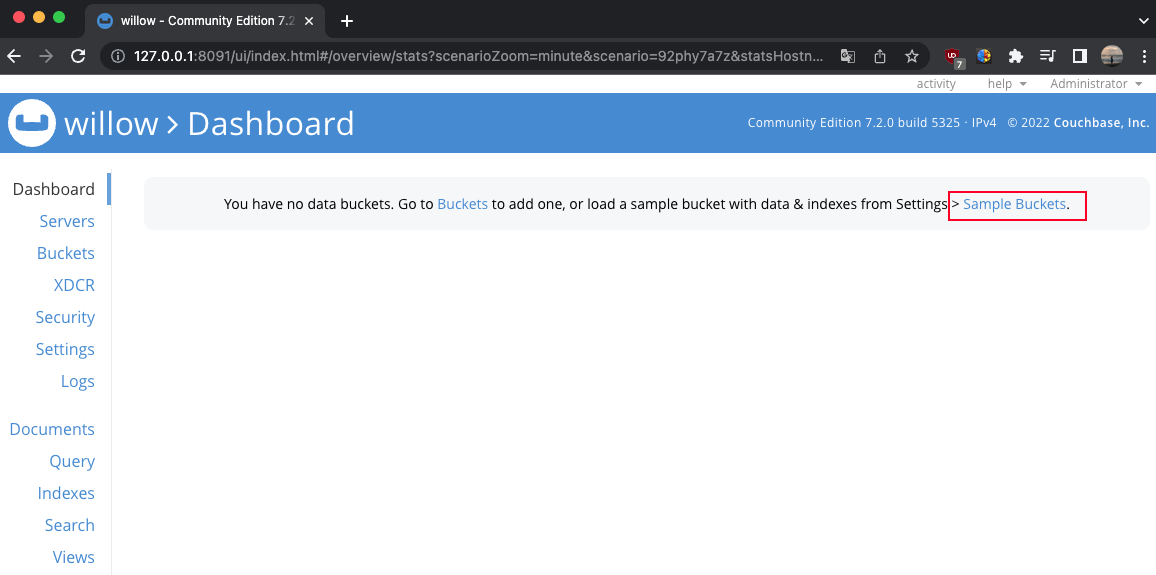
travel-sample 버킷으로 생성해보겠습니다.
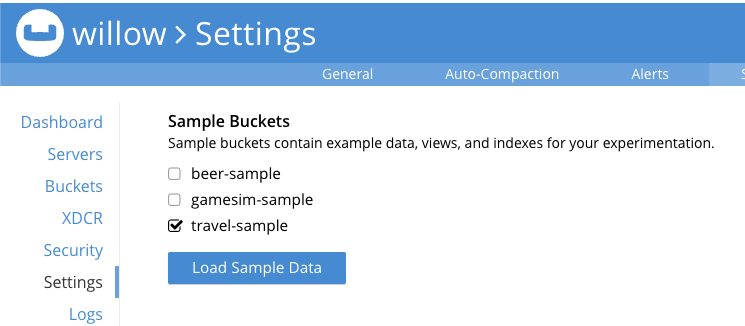
travel-sample 버킷 Documents 를 확인해볼까요?
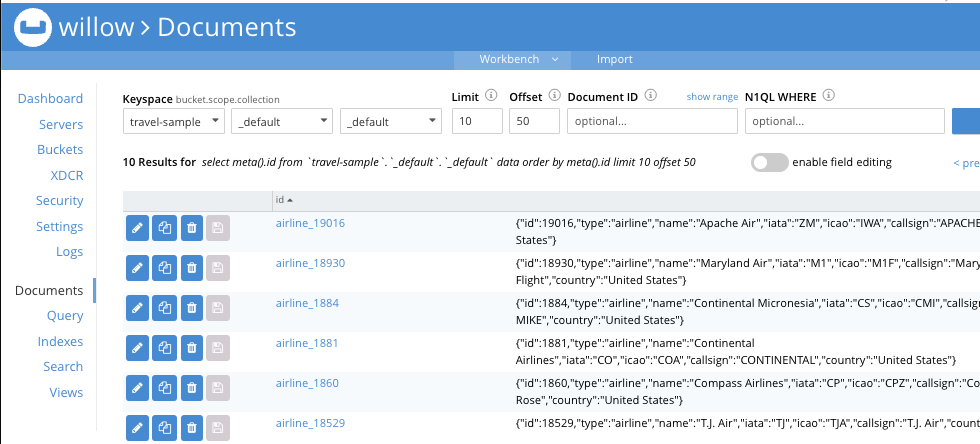
travel-sample 버킷 생성후 얼랏 메세지가 발생하였습니다.
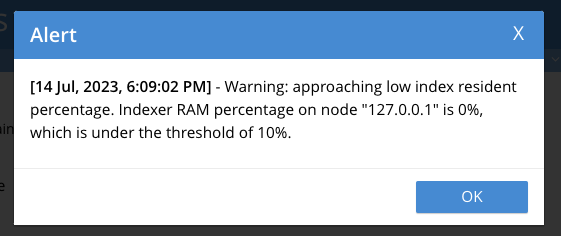
Warning: approaching low index resident percentage. Indexer RAM percentage on node "127.0.0.1" is 0%, which is under the threshold of 10%.
번역하자면
경고: 낮은 지수 상주 비율에 근접하고 있습니다. 노드 "127.0.0.1"의 인덱서 RAM 백분율은 0%이며 임계값 10% 미만입니다.
얼랏 메세지를 확인 못했다면 Logs 메뉴에서도 확인가능합니다.
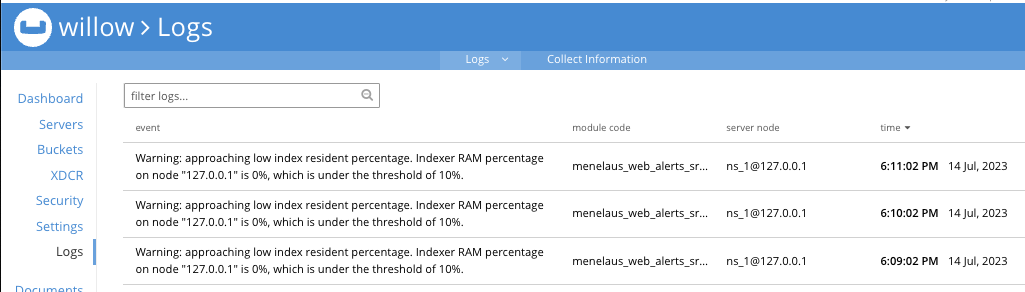
16G 중 20% (3.2G)는 OS 에 제공되고, 그러면 12.8G 가 남습니다. 3개 서비스 (Query, Index, Serarch) 에 간각 분할 되면 4.2G(12.8/3)가 할당됩니다. 인덱스 서비스에 대한 메모리 할당량을 초과한 것으로 의심됩니다. 이것이 일부 인덱스에서 상주 비율이 낮은 이유입니다.
출처 https://www.couchbase.com/forums/
Index 설정값이 사이즈가 작아서 512 MiB > 1024 MiB로 변경했습니다.
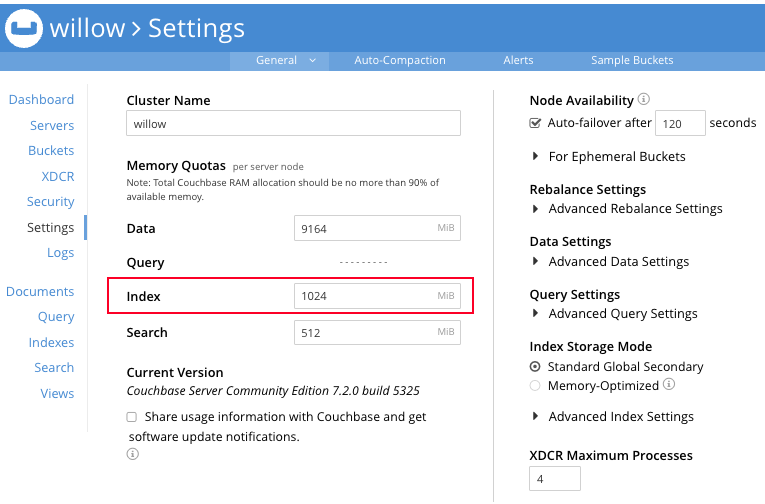
Index 설정값 변경시 인덱스가 잠시 중지된다는 안내를 보여주는군요.
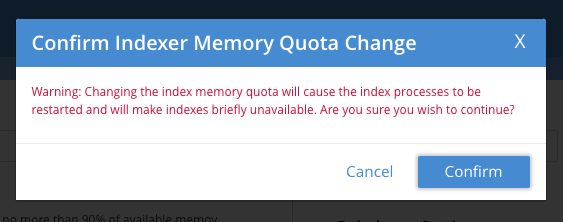
Warning: Changing the index memory quota will cause the index processes to be restarted and will make indexes briefly unavailable. Are you sure you wish to continue?
번역하자면
경고: 인덱스 메모리 할당량을 변경하면 인덱스 프로세스가 다시 시작되고 인덱스를 잠시 사용할 수 없게 됩니다. 계속하시겠습니까?
변경 후 알림 로그 발생되지 않는군요.
Use
Couchbase Workbench 사용을 해볼까요?
Query workbench 사용안내 를 참고 할 수 있습니다.
Query
기본적인 사용법입니다.
select meta().id from `travel-sample`.`_default`.`_default` data order by meta().id limit 10 offset 10
select meta().id from `travel-sample`.`inventory`.`airline` data order by meta().id limit 10 offset 0
Document ID : airline_18241
{
"id": 18241,
"type": "airline",
"name": "Royal Airways",
"nick_name": "willow",
"iata": "KG",
"icao": "RAW",
"callsign": "RAW",
"country": "United States"
}
select * from `travel-sample`.`_default`.`_default` data where meta().id = 'airline_18241'
전체 Doucumnt 에 항목 추가
UPDATE `travel-sample`.`_default`.`_default` data
SET city = 'Seoul'
RETURNING data;
The current dataset, 95764626 bytes, is too large to display quickly.
1개 Document 에 city value 변경
UPDATE `travel-sample`.`_default`.`_default` data
USE KEYS "airline_18241"
SET city = 'Busan'
RETURNING data;
2개 Document city value 변경
UPDATE `travel-sample`.`_default`.`_default` data
USE KEYS ["airline_10", "airline_10123"]
SET city = 'Gwangju'
RETURNING data;
1개 Doucment 삭제
DELETE FROM `travel-sample` WHERE META().id = 'hotplace_02'
1개 이상 Doucment 삭제
DELETE FROM `travel-sample` WHERE META().id IN ['hotplace_01', 'hotplace_02']
배열 조회
key-value 구조에서 value 에 배열의 형태로 데이터가 있는경우 배열 중 하나만 있는 경우 조회를 해보겠습니다.
먼저, Document 를 생성하겠습니다.
Sample Data 를 만들어봤습니다.
INSERT INTO `travel-sample` ( KEY, VALUE )
VALUES
(
"hotplace_01",
{
"area" : "Yangyang",
"shops" : [
{
"shopId" : "1",
"shopName" : "Yangyang-shop1",
"shopItem": [
"A",
"B",
"C"
]
},
{
"shopId" : "2",
"shopName" : "Yangyang-shop2",
"shopItem": [
"D",
"E"
]
}
]
,"type": "hotplace"
}
),
(
"hotplace_02",
{
"area" : "Sokcho",
"shops" : [
{
"shopId" : "1",
"shopName" : "Sokcho-shop1",
"shopItem": [
"A"
]
}
]
,"type": "hotplace"
}
)
RETURNING META().id as docid, *;
1개 Document 조회해보겠습니다. _default 는 생략해도 된답니다.
SELECT * FROM `travel-sample` WHERE META().id = 'hotplace_02'
SELECT * FROM `travel-sample`.`_default`.`_default` WHERE META().id = 'hotplace_02'
shop 1개 Document만 조회해보겠습니다.
SELECT s.* FROM `travel-sample` t UNNEST shops s WHERE META(t).id = 'hotplace_01' AND s.shopId = '1'
Results
[
{
"shopId": "1",
"shopItem": [
"A",
"B",
"C"
],
"shopName": "Yangyang-shop1"
}
]
판매하는 상품(shopItem)중에 B 상품을 판매하는 상점은 어디일지 조회해야 하는 경우가 생겼습니다.
Document id 를 아는경우는 아래와 같이 조회하였습니다.
소요시간 3.3ms
SELECT
t.area, s.shopName, s.shopId
FROM `travel-sample` t
UNNEST shops s
WHERE META(t).id = 'hotplace_01'
AND "B" IN s.shopItem
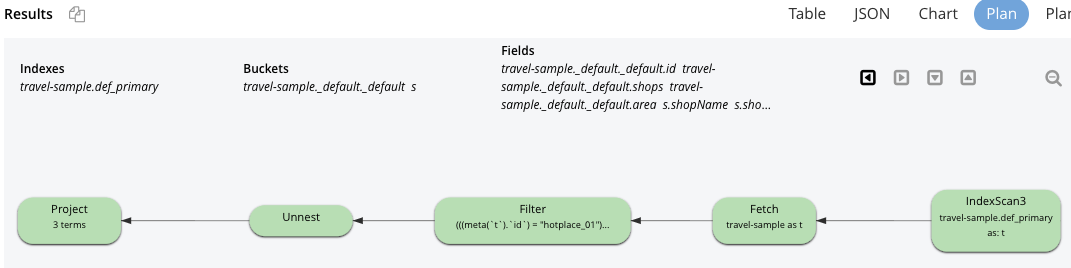
Document id 를 모르는 경우입니다.
Index를 타지는 않아 느리지만 결과는 가져오는군요.
소요시간 274.6ms
SELECT
t.area, s.shopName, s.shopId
FROM `travel-sample` t
UNNEST shops s
WHERE "B" IN s.shopItem

ArrayIndex 를 적용해보려고 합니다.
참고한 블로그 에서는 배열안에 Object 형태라서
위의 조건과 좀 다르지만 일단 적용해 보았습니다.
CREATE INDEX index_shop_item ON `travel-sample`.`_default`.`_default` (DISTINCT ARRAY v FOR v IN shopItem END)
WHERE type = "hotplace"
기존 조회하는 쿼리에 인덱스 선언문만 추가해서 실행해 보았습니다.
소요시간 2.9 ms
SELECT
t.area, s.shopName, s.shopId
FROM `travel-sample` t
USE INDEX(index_shop_item)
UNNEST shops s
WHERE t.type="hotplace" AND "A" IN s.shopItem
신기한점은 Query Plan에 index_shop_item 인덱스를 사용하지 않는데 빠르게 조회됩니다.